



How Does Web Scraping Become Simpler and How To Prevent It? (With Scraping NBA Players' Salary Example)
06 Sep 2021 • 10 min read
How Does Web Scraping Become Simpler and How To Prevent It? (With Scraping NBA Players' Salary Example)


06 Sep 2021 • 10 min read
Introduction
Web scraping refers to extracting the content of a website programmatically. Specifically, developers create bots to get the HTML code of a website, parse the code and export the result to an external data source.
Developers do it for different purposes. Search Engines scrape data from websites and further index it so that we can find information much easily. However, there are quite a lot of bad bots on the internet (25.6% of all website traffic comes from bad bots), these bad bots may try to steal your content, e.g. Data Leak in Alibaba's Taobao due to web scraping.
Web Scraping On NBA Players' Information
Today, web scraping becomes much easier due to technology advance, which we will illustrate it by a simple example, how to scrape NBA players' information, e.g. Height, Birthdate, salary.
Here's the main page of NBA players' basic information:
https://hoopshype.com/salaries/players.
We can navigate to another web page that contains each player's basic information from this page.
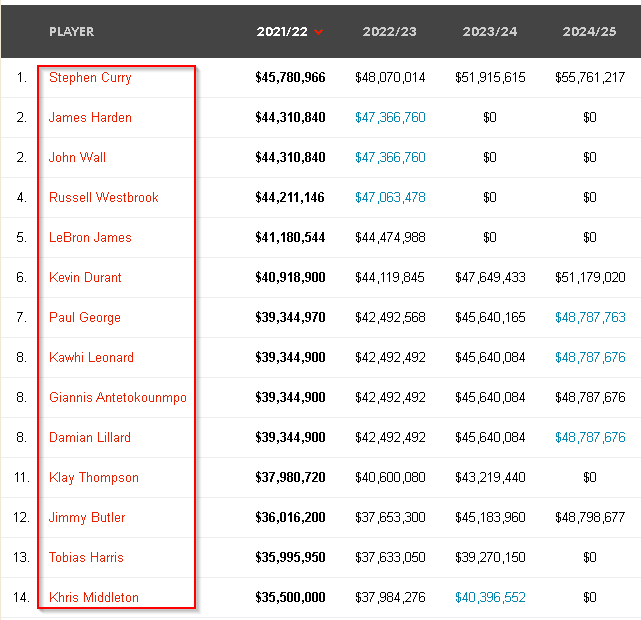
Main page
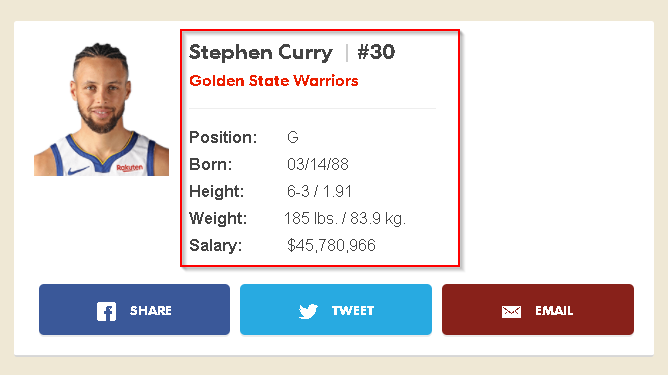
Stephen Curry's basic information
Prerequisite
Basic Python & HTML knowledge is required.
We will use Python for web scraping, these are Python modules that we will use
Selenium Driver Installation
To let Selenium module functions, we need to install Selenium driver. The driver depends on the operating system of your machine and the version of your web browser.
We will illustrate the installation steps for Windows, you may refer to https://selenium-python.readthedocs.io/installation.html#drivers for more detail.
1.Download the zip file containing the chromedriver.exe


2.Unzip the folder. Optionally, you can move the folder to another directory
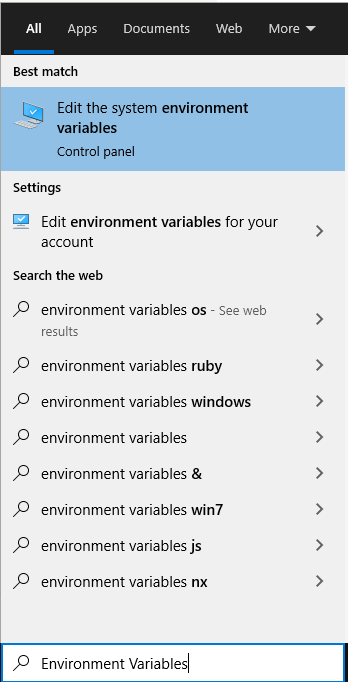
3.Type "Environment Variables" in start menu & select "Edit the system environment variables"
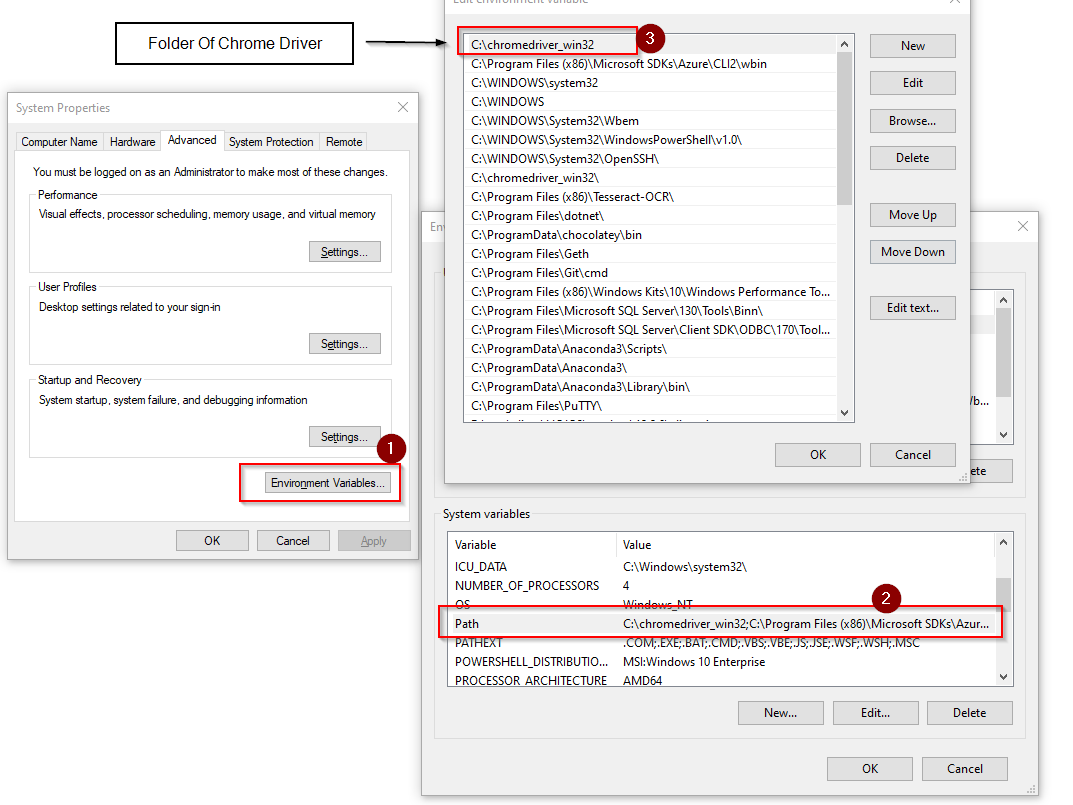
4.Update PATH variable to include the folder path which contains the driver program
Get HTML code of the website
First of all, let us try to use Selenium to launch a new browser & get the source code of NBA players' salary data source.

You should get the HTML code as below.

On the other hand, you should see a new browser is launched.

Navigate to NBA player's basic information page
In order to get each player's basic information, we need to navigate to the corresponding page & extract the data. The links of these pages are already in a table of the main page.
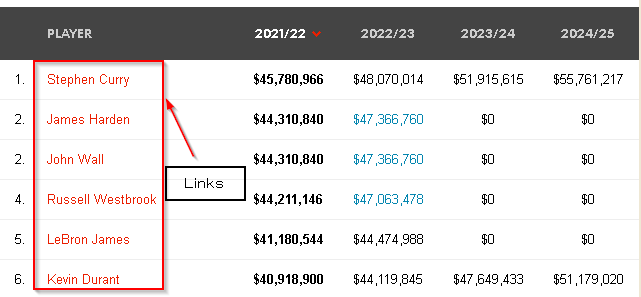
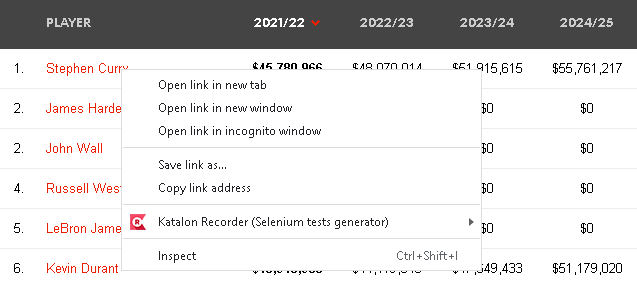
To get the links in this table, we can find the corresponding HTML elements. We can use the below method to find the HTML element of those links of NBA players' basic information page.
1.Right click one of the links
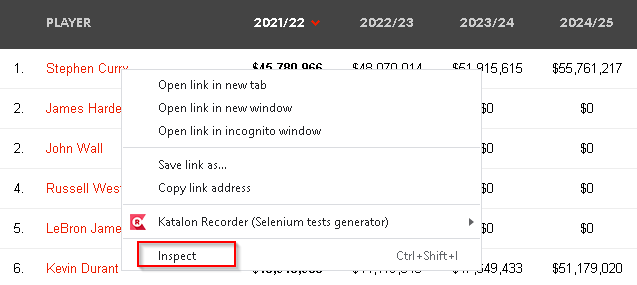
3. Developer tool should appear & the corresponding HTML element should be highlighted.
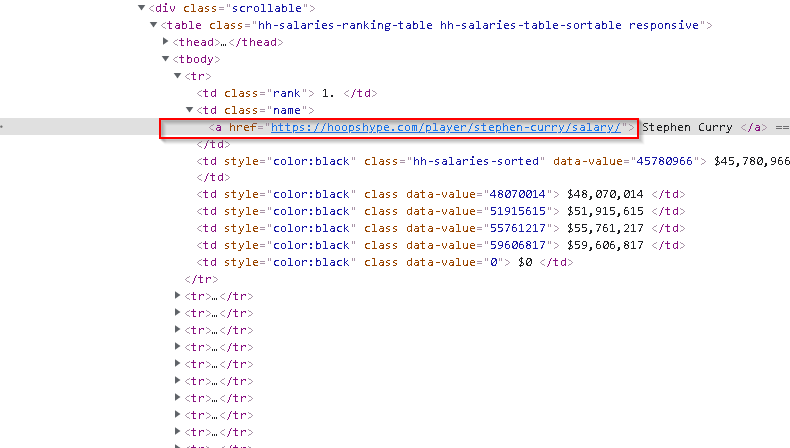
4.HTML elements for other players are similar to this one.
Next, we use Beautiful Soup to extract the links of basic information page for all players.

There are numerous ways to query the HTML code with BeautifulSoup. Here, we locate the salary table by "table tag" & its classes, then extract all links inside it.
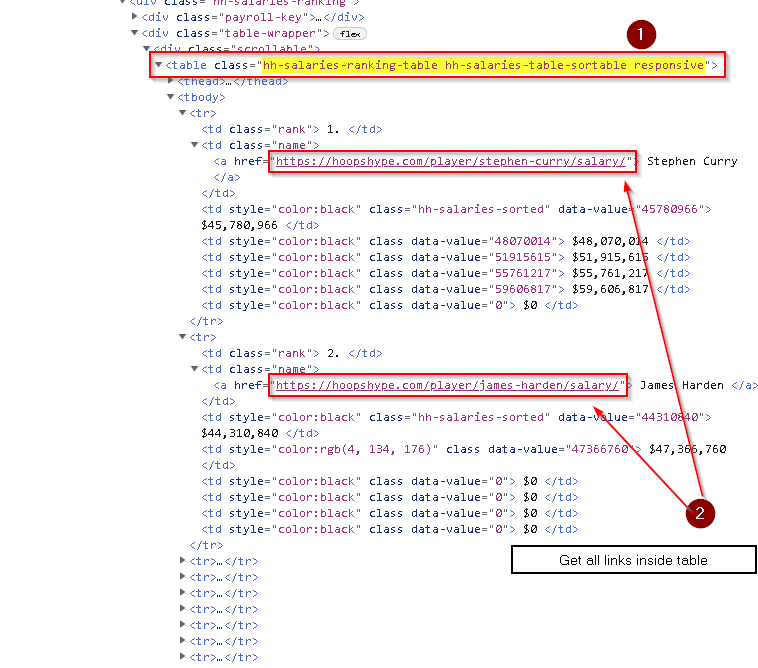
Extract basic information
After getting the link to each player's basic information page, we will extract the basic information for each user. Most of those pieces of information are text and non-clickable, we need to locate its element by highlighting them and right clicking as below.
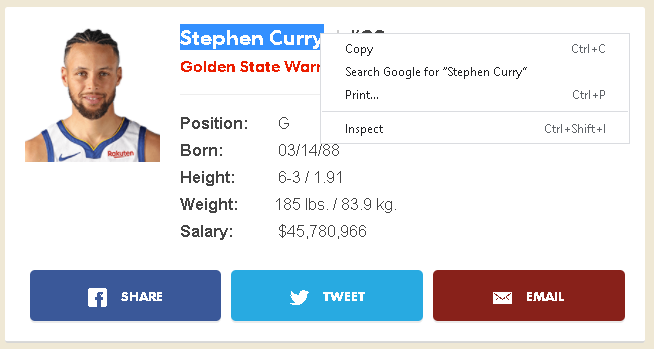
Once again, you can use BeautifulSoup to extract the elements of those
pieces of information by performing certain queries.

Unfortunately, there is no way to identify position, birth date, height, weight and salary, as all of them share common attributes. Therefore, we get all relevant elements and match them one by one.
The output should look like this.

Repeat the steps for each player
After being able to extract the information from a player, we just need to repeat the whole process for each player and store the information.

Export result to a csv file
We convert the data to a table-like format

You should see a table as below.

Finally, we export the information as a csv file

Conclusion
The above tutorial outlines how to scrape data from web pages with just three python modules. In fact, anyone who has basic knowledge of Python & HTML can learn web scraping quickly given that there are lots of mature tools. In other words, anybody can steal your web content easily if you have zero protection on your web content. Therefore, it becomes crucial to protect your content by adopting Cyber Security technologies.
These technologies can monitor your websites' traffic, verify the authenticity of incoming traffic & block the incoming traffic. For example, Geetest’s BotSonar, which is adopted by multinational companies, e.g. KFC & Nike, that technology monitors your website 24/7 and distinguishes the traffic between bad bots and human beings by their AI technology. On top of that, you can choose how do you handle those bad incoming traffic, e.g. blocking the bad incoming traffic or showing fake content to them. Besides, Geetest respects your data privacy, their products are GDPR compliant, which is a plus if you are from enterprise background.
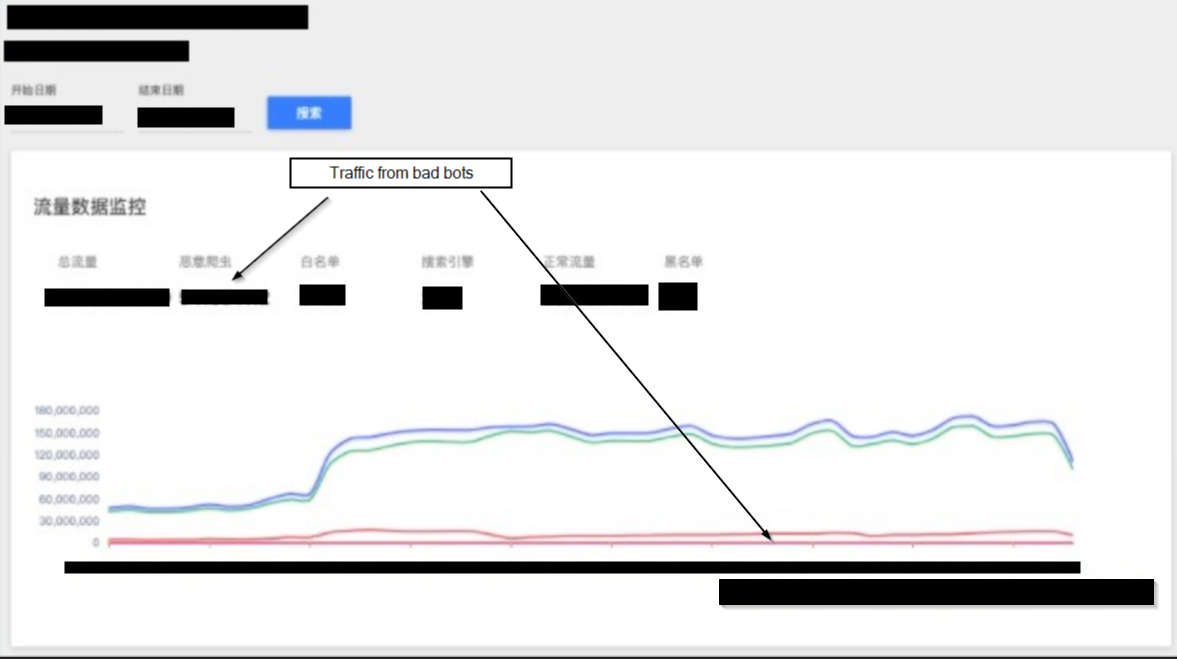
Geetest's anti web scraping
Wrote By:Joe
Source Code
Source code is available at
https://github.com/JoeHO888/How-does-web-scraping-become-simpler-and-how-to-prevent-it/blob/main/How
does web scraping become simpler and how to prevent it - Source Code.ipynb
GeeTest
GeeTest
Subscribe to our newsletter





