



GeeTest's AIGC Journey: Reshaping CAPTCHA Verification and Bot Mitigation
26 May 2023 • 10 min read
GeeTest's AIGC Journey: Reshaping CAPTCHA Verification and Bot Mitigation


26 May 2023 • 10 min read
Since GeeTest pioneered the new generation of intelligent CAPTCHA in 2013, we've been at the forefront of evolving and enhancing bot detection & mitigation technologies. Adopted by nearly 400,000 developers worldwide over the past decade, our ground-breaking "Behavioral Verification" has not only improved user experience but has also fortified the battle against bot-generated fraudulent activities. Leading companies such as Binance, Imperva, miHoYo, and Agoda have integrated our CAPTCHA into their systems, transitioning away from traditional verification methods.
In this ever-advancing cybersecurity landscape, we at GeeTest have consistently pushed boundaries, exploring and integrating cutting-edge technologies. From the early adoption of Neural Style Transfer technology in 2016, we've sought the perfect balance between user experience and security.
![]()
The working mechanism of Neural Style Transfer (Image Source)

GeeTest's innovation integrating "semantic understanding" with "Neural Style Transfer", protected by patent ZL 201830130077.X (Source: GeeTest)
Today, as the realm of AI-Generated Content (AIGC) - including Text-to-Image models, Large-scale Text-to-Image Generation Models (LTGMs), Large Language Models (LLMs), and beyond - continues to evolve, we seize every opportunity to learn, experiment, and assimilate these advanced technologies to further enhance our bot protection strategies.
This article takes you behind the scenes of our exploration into these generative AI technologies, offering insights into our process, progress, and intriguing experimental results.
Understanding Text-to-Image Models
Text-to-image models represent a pioneering approach within Multimodal Deep Learning. They can produce images that semantically correspond to text descriptions. Through the process of connecting visual features and linguistic information, these models bridge the gap between textual prompts and their visual counterparts.
Trained on extensive datasets containing paired natural language descriptions and corresponding images, these models extract key features from the text and map them onto the visual representation in the images. The training process involves sophisticated semantic comprehension and image synthesis.
With this training, the models can generate images from previously unseen textual descriptions. The text is first encoded into a feature vector, which then facilitates the synthesis of a corresponding image through a generator network.
The applications of these models span across several domains, covering the creation of realistic product images for e-commerce websites, development of visual aids for individuals with disabilities, generation of images for virtual and augmented reality applications, and production of CAPTCHA images.
Addressing Challenges in AI Image Generation
In my work with AI image generation, I've found that there are several challenges to be addressed in terms of accuracy, controllability, and scalability.
Accuracy
One of the main issues with AI image generation processes relates to accuracy. It's clear that most pre-trained models are designed around English, which often leads to translation-induced ambiguities and mismatches between text and images. A word with multiple meanings can cause significant confusion.
For example, the images shown below represent a classic case of translation ambiguity. The English term "crane" can refer to either a construction machine or a bird, hence the model generates both types of images.

Source: GeeTest
Here, we illustrate another challenge faced when generating images based on our existing prompt library. For instance, when the prompt is "electric mouse", the term "mouse" — which could signify an animal or a computer peripheral in English — was mistranslated to signify an actual "mouse", resulting in generated images depicting only the rodent. Furthermore, a conspicuous mismatch can be noted in the image at coordinates [1,2], where the generated image bears no relation to the provided prompt.

Source: GeeTest
Similarly, this issue of semantic inconsistency persists with the prompt "can". While typically referring to an aluminum container, it unexpectedly generates a variety of unrelated images, including a cat, an aluminum suitcase, an aluminum beverage can, and a barn-like structure, among others.

Source: GeeTest
Next, we present an instance where the model, switched to a cartoon style, and encountered both semantic ambiguity and sensitivity. Using the same prompt "electric mouse", we observed a variety of responses. Remarkably, it produced images ranging from mice (the animal) morphed into the form of computer mice, to anime characters exhibiting mouse-like features. This encounter demonstrates that the challenges persist across styles and contexts, reaffirming the need for careful attention and innovative solutions in AI image generation tasks.

Source: GeeTest
These instances underline the need for models to better handle language nuances and improve the accuracy of the images generated. An avenue to explore is the open-source project like Fengshenbang-ML, constructed based on Chinese by the IDEA-CCNL. Given its localized structure, Fengshenbang could serve as a potential solution to accuracy-related issues in the context of Chinese language applications. Yet, in large-scale applications, the blend of advanced AI and human supervision remains critical to ensuring appropriate image generation.
Controllability
Addressing sensitive materials and issues of fairness and bias can be partially resolved with safety-checker. However, implementing additional measures can significantly enhance these mitigation efforts:
- Diverse Data Collection: Ensuring that datasets used for image generation are representative, encompassing individuals and scenes from various backgrounds, cultures, and races to produce unbiased images.
- Equitable Model Training: Employing fair and equitable methods when training text-to-image models. Techniques like "fairness constraints" ensure that generated images are free from discriminatory features. Specifically, models are trained to avoid discriminatory attributes such as age, race, gender, and others, thereby eliminating potential biases.
- Supervision and Auditing: Regular human supervision and auditing during the model training and image generation stages ensure images meet ethical and moral standards.
- Avoiding Sensitive Topics: Steering clear of generating images related to race, gender, religion, politics, or other sensitive subjects.
- Transparency: Making public the training methods, datasets, and auditing procedures helps the community understand the use and potential impacts of these technologies.
Scalability
In the sphere of AI image generation, scalability plays a critical role, especially in the context of mass content production. Achieving scalability requires careful computational resource planning and GPU resource allocation. This involves addressing three core demands:
- Model Servicing: Large models, by their very nature, necessitate the use of GPU invocation. This resource, while indispensable, can be cost-prohibitive, especially when acquired from cloud-based services.
- Resource Optimization: Initially, to manage one-time investments effectively, the approach would be to utilize GPU resources on a pay-as-you-go basis. This strategy avoids hefty monthly rentals and promotes efficient resource usage.
- Efficient Scaling: It's imperative that the codebase for model servicing remains as compact as possible, facilitating straightforward horizontal scaling.
Responding to these pressing needs, we've built a model service architecture leveraging Ray and K8s. This system enables a minimalist approach to code volume in model service deployment while providing flexibility for easy horizontal scaling.

A model device based on Ray and K8s (Source: GeeTest)
As illustrated above, the unique architecture enables us to deploy a model service with the least possible code volume.
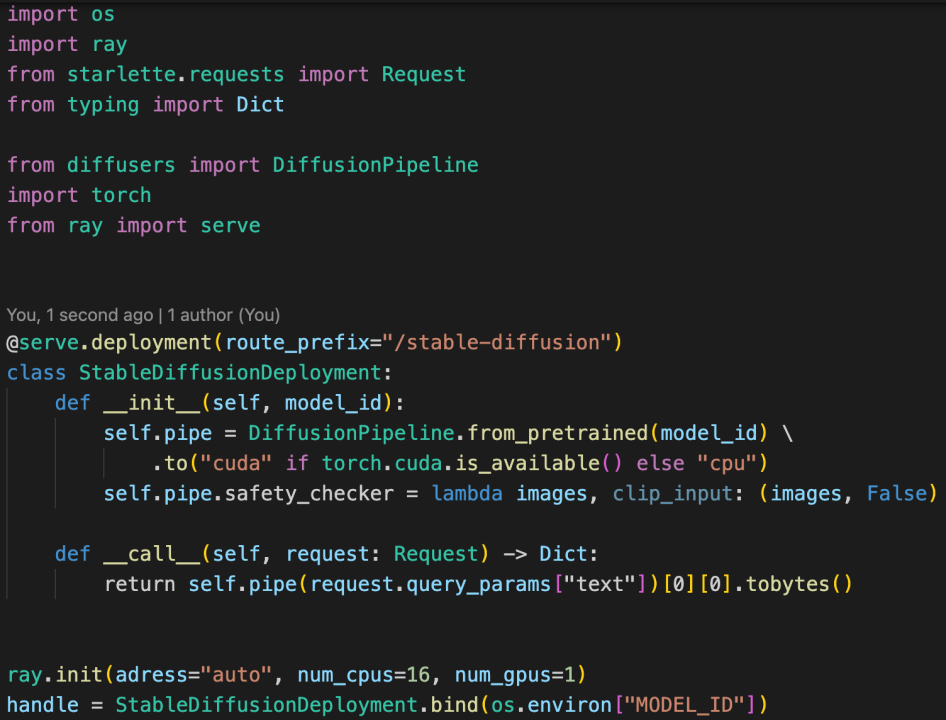
.png)
Source: GeeTest
These strategic improvements significantly bolster scalability and agility – both of which are vital for the large-scale application of AIGC in bot mitigation strategies.
Integrating Generative AI into GeeTest CAPTCHA Frameworks
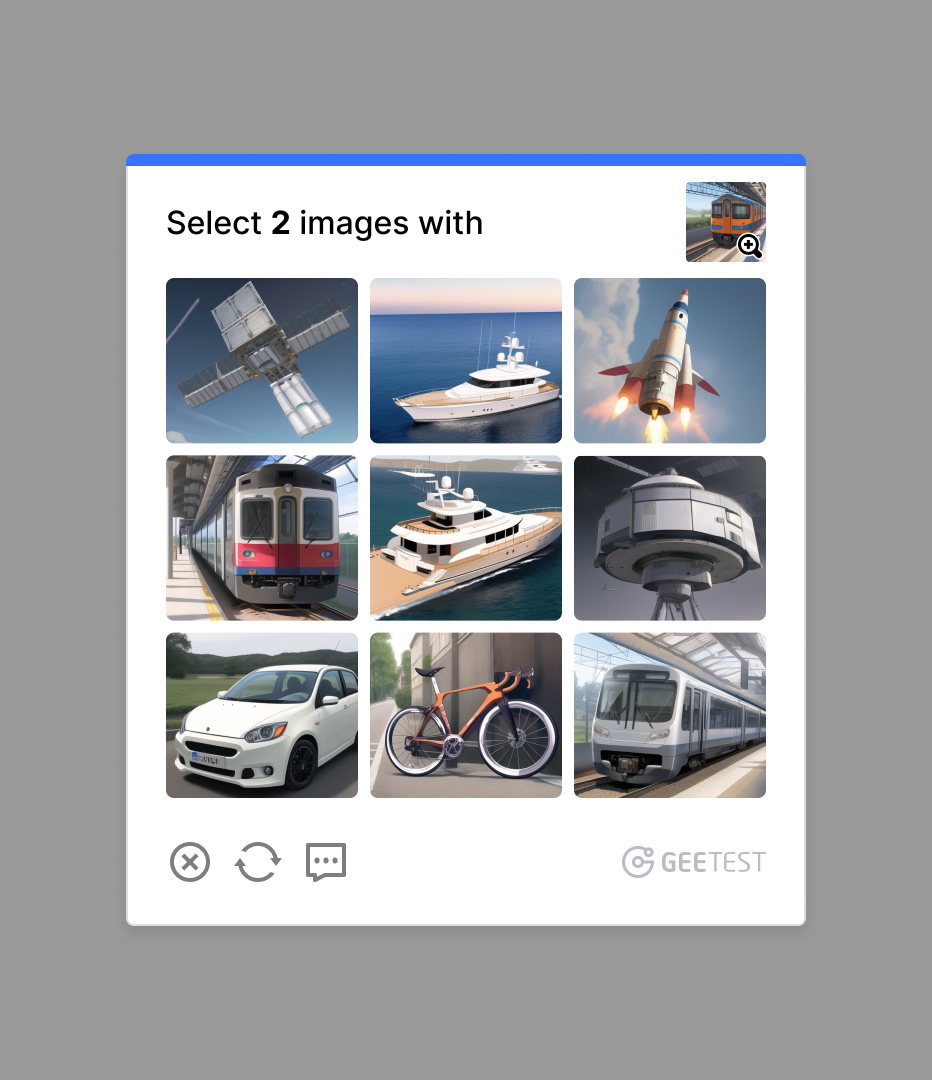
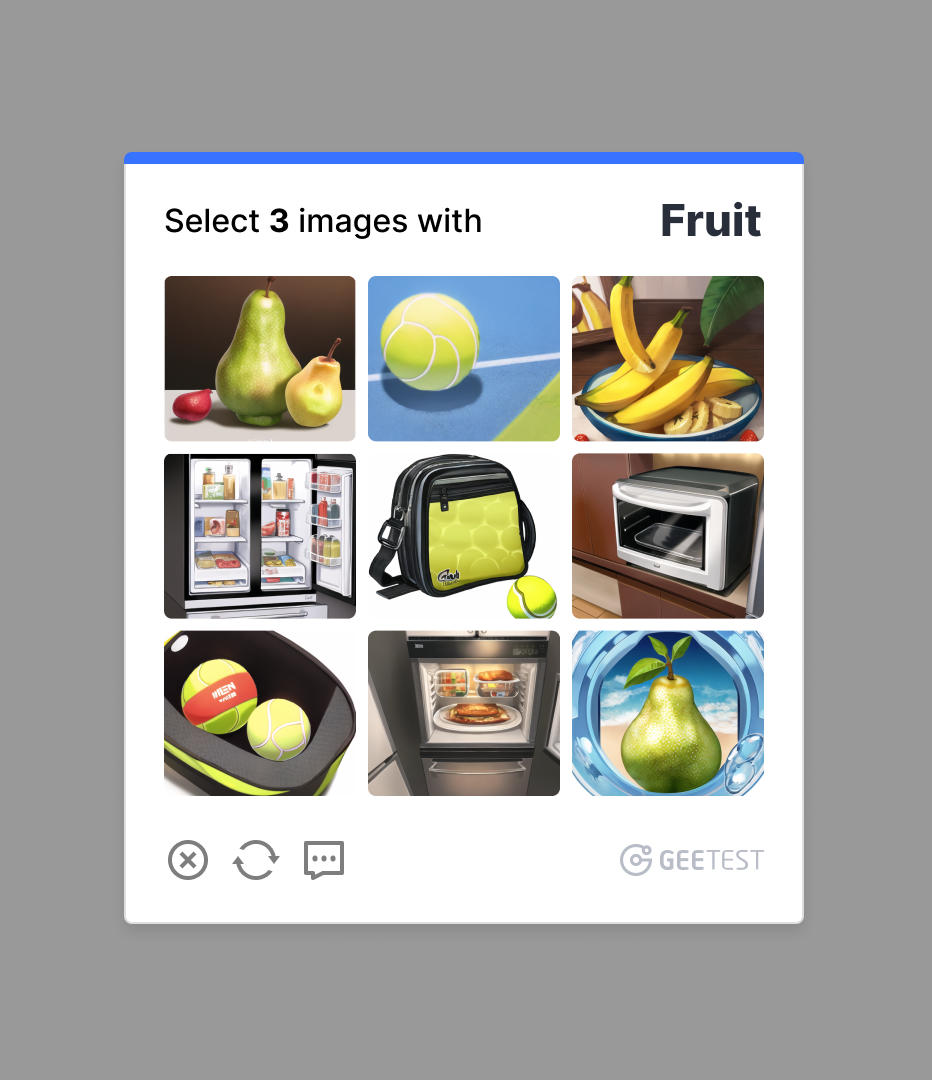
Real-world applications of GeeTest CAPTCHAs generated by Generative AI Models (Source: GeeTest)
Looking Ahead
As we've explored, the integration of Generative AI technologies into GeeTest's bot mitigation strategies brings promising possibilities, yet also presents intriguing challenges. Our proactive approach to resolving accuracy, controllability, and scalability issues has paved the way for significant advancements in CAPTCHA technology. As we look to the future, our focus remains on developing advanced AI image generation techniques to combat threats like "ML model cracking" and "CAPTCHA solving farms". These forms of attacks often work in conjunction, where manual labor initially solves CAPTCHA for bots, followed by the utilization of AI/ML algorithms to train models for automatic cracking. Therefore, our focus lies in enhancing the updating speed of images and their resistance against model cracking.
Currently, GeeTest processes billions of daily API calls and maintains a stringent service solution, backed by our extensive experience in image security. We ensure automated updates of our entire online image resources every hour, incorporating 50,000 images across 200 categories. For clients with higher instantaneous requirements, we offer automated updates of 10,000 images in 50 categories every 10 minutes.
I look forward to sharing more about our ongoing explorations and trials in the world of AI-generated content (AIGC). We'll also dive into more real-world adversarial examples using LTGMs, discussing in detail how our models offer anti-cracking advantages in CAPTCHA verification and bot prevention. The journey continues, and I'm excited for what lies ahead.
.png)
Jiahao Cao
Senior Software Engineer | GeeTest
Subscribe to our newsletter





